

今晚,DeepSeek正式推出两个全新正式版模型:DeepSeek-V3.2(标准版)与 DeepSeek-V3.2-Speciale(特别版)。
从公开报道的数据来看,V3.2标准版在公开推理Benchmark中达到GPT-5水平,仅略逊于Gemini-3.0-Pro,同时显著优化输出长度与响应效率,适用于日常问答、通用Agent等高频率场景。
而V3.2-Speciale特别版则聚焦极限推理能力,在IMO、CMO、ICPC、IOI等全球顶级竞赛中斩获金牌,其数学证明与逻辑验证能力已逼近人类顶尖选手水平。
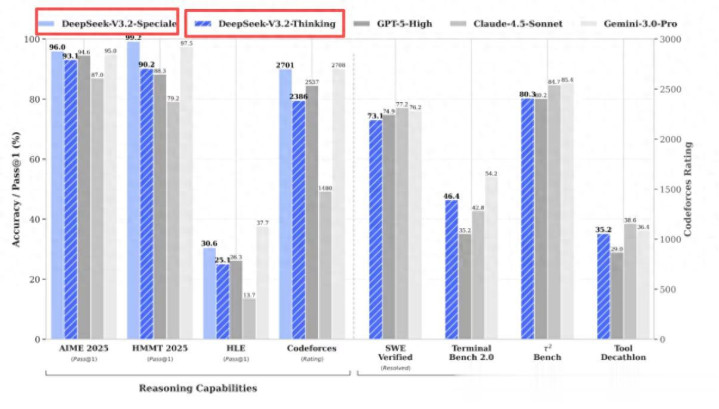
另外就是,V3.2是DeepSeek首个实现“思考模式下仍可调用工具”的模型,彻底打破此前“思考即封闭”的技术瓶颈,并同步支持非思考模式下的工具调用。
简单来说就是,性能更加好了,反应速度更快了,数据处理更强了。
DeepSeek-V3.2的迭代对国产算力有什么影响?
过去,国产芯片往往需要围绕已有模型(如LLaMA、GPT)进行兼容性适配,处于技术跟随地位。
而DeepSeek-V3.2引入了自研稀疏注意力机制(DSA)、思考-工具融合架构、大规模Agent合成训练流程等原创设计,这些特性在主流开源模型中并无先例。
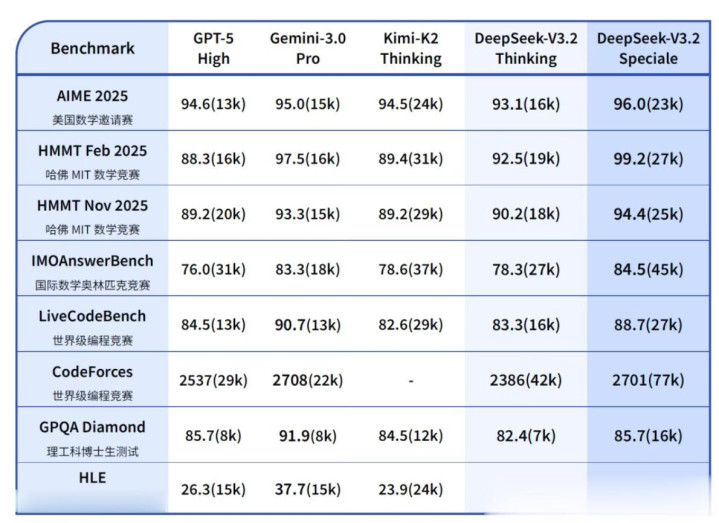
从这方面来看,国产芯片在某些情况之下,可高效运行V3.2,不能简单照搬CUDA生态或Transformer通用优化策略。
另外,DeepSeek作为模型方,实际上设定了新一代AI负载的“接口规范”和“性能基准”,国产算力厂商或许需主动对接其技术路线,形成“模型定义硬件”的新范式。
另外就是DeepSeek-V3.1发布后,昇腾、寒武纪、海光等厂商几乎同步宣布完成适配,并开源推理代码与算子实现。
这或许说明,国产芯片已能稳定运行国内前沿的大模型架构,侧面验证了可用性。
DeepSeek-V3.2带来新增需求在哪里?
DeepSeek-V3.2系列的发布,或许可以看到国产大模型演进对算力基础设施提出的特殊方面的要求:
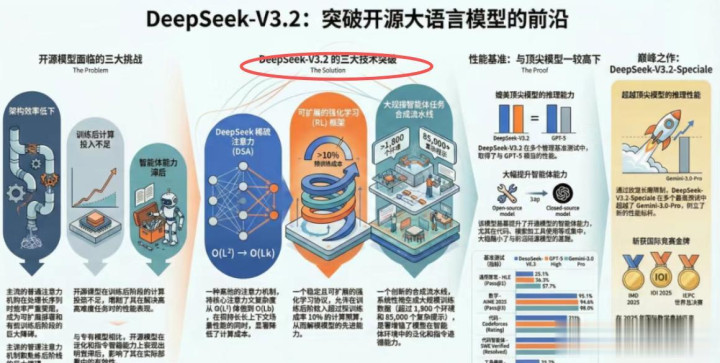
1、后训练算力占比跃升
参考公开报道,结合行业趋势及V3.2在强化学习上的显著提升,可判断其后训练(Post-training)资源投入或许远超传统微调范畴。
这类基于Agent反馈的训练,需要高频仿真、快速迭代与大规模并行,对训练集群的稳定性、调度效率和能耗控制提出极高要求。
2、长上下文推理需求
尽管V3.2优化了输出长度以降低开销,但其支持的长思考链与工具调用仍依赖高效处理长序列的能力。
DeepSeek自研的稀疏注意力机制(DSA)虽能压缩计算量,但对内存带宽、访存局部性、定制化加速单元的依赖反而更强,通用GPU难以发挥最优效能。
3、Agent仿真训练引爆“数字世界”算力消耗
1800+虚拟环境并非简单数据集,而是需实时运行的交互式仿真系统。
每一次Agent决策都涉及环境状态更新、奖励计算与策略回传,本质上是大规模并行智能体训练
这类负载兼具CPU密集型(环境逻辑)与GPU密集型(策略网络),推动算力需求从“单一模型训练”向“AI+仿真+数据闭环”复合型基础设施演进。
对国产算力有什么影响?
过去,国产算力或许更多被视作“替代选项”。
但如今,随着DeepSeek等头部模型厂商主动拥抱自主技术栈,国产算力或许正从被动适配转向主动协同下一代AI基础设施。
DeepSeek引入了多项原创架构设计:
自研稀疏注意力机制(DSA)
思考-工具融合架构
大规模 Agent 合成训练流程
这些特性在主流开源模型中并无先例,意味着不能简单套用 CUDA 生态或传统 Transformer 优化策略。
国产算力芯片若想高效运行 V3.2,必须深入理解其底层逻辑,甚至可能反向推动硬件创新。
事实上,就在 V3.2 发布后不久,昇腾、寒武纪、海光等国产芯片厂商几乎同步宣布完成适配,并开源了推理代码与定制算子实现。
这不仅体现了快速响应能力,更侧面验证了:国产算力已能稳定支撑国内前沿的大模型架构。
换句话说,模型或许开始定义硬件,DeepSeek 作为模型方,正在设定新一代 AI 负载的“接口规范”与“性能基准”,而国产算力厂商正从被动适配转向主动协同。
写在最后
DeepSeek-V3.2的双版本发布,不仅是算法能力的跃迁,更可能是对下一代AI基础设施的选择。
通过模型与硬件的深度协同,国内有望在全球AI基础设施竞争中走出一条高效、可持续的发展路径。
这方面或许值得我们关注。
特别声明:以上内容绝不构成任何投资建议、引导或承诺,仅供学术研讨。
如果觉得资料有用,希望各位能够多多支持,您一次点赞、一次转发、随手分享,都是笔者坚持的动力~
天创网提示:文章来自网络,不代表本站观点。



